 手機版|
手機版|

 二維碼|
二維碼|
會議時間:2018-01-27 08:00:00至 2018-01-28 18:00:00結束
會議地點:北京
聯系電話:028-69761252
培訓特色
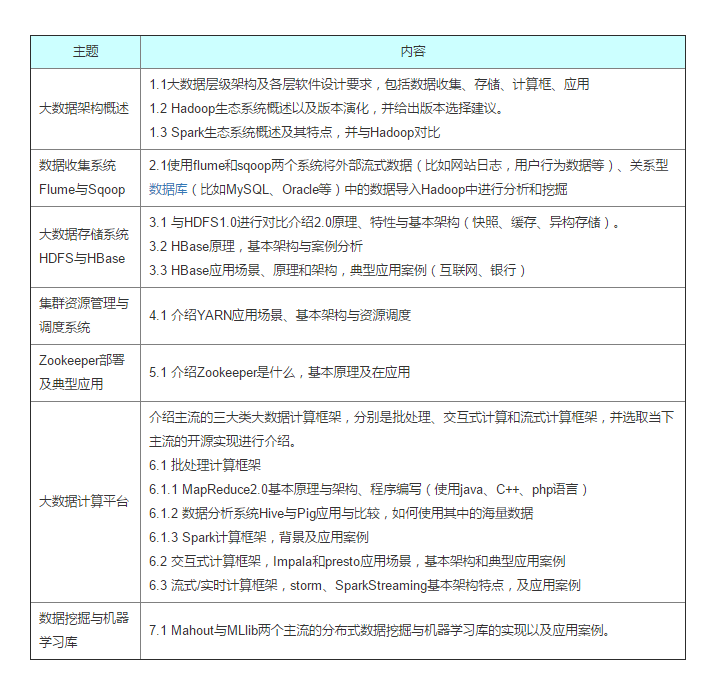
當下是大數據時代,為構建大數據平臺,需要對分布式數據收集,大數據存儲,分布式計算,資源管理等系統有全面而又深入的理解。眾所周知,大數據源自于互聯網行業,目前互聯網公司已有一套完善的大數據平臺建設方案,大部分選用開源的Hadoop和Spark兩大生態系統,本課程正是以這兩套系統為主介紹大數據平臺及架構的構建策略及經驗。
目標收益
本課程將為大家全面而又深入的介紹大數據平臺的構建流程,涉及分布式數據收集,大數據存儲,資源管理及分布式計算框架等。本課程重點以Hadoop和Spark兩大生態系統作為基準進行介紹,涉及Flume,HDFS,Hbase,YARN,MapReduce,Hive,Zookeeper,Spark,Storm,SparkStreaming等主流的大數據開源系統架構及應用經驗。
培訓對象
各類IT/軟件企業和研發機構的軟件架構師、軟件設計師、程序員。對于懷有設計疑問和問題,需要梳理解答的團隊和個人,效果最佳。
學員基礎
了解Java語言、Linux系統;
課程時長
2天
課程大綱
講師介紹
畢業于大連理工大學,本科,有多年大數據分析類大型項目的架構實施經驗,目前任職TD,先后服務于北京大學軟件研究所、高德軟件、阿里巴巴和Teradata,實施過基于Hadoop平臺PageRank算法的實現、高德大數據中心的建設(300+的Hadoop集群開發、優化、運維和提供服務)、阿里巴巴OPDS大數據平臺維護、內蒙移動大數據平臺試點(Hadoop)、臺灣遠傳Hadoop平臺開發和優化、蘭州銀行大數據平臺的架構和開發(Hadoop)、招商銀行的大數據咨詢規劃和設施。在大數據架構、數據集成、數據挖掘/機器學習、實時推薦和營銷方面有豐富經驗,了解大數據在互聯網的使用場景。
1)編寫并出版《Hadoop應用開發技術詳解》圖書,銷售10000+冊——機械工業出版社(2014-01)
2)專利《海量數據基于記錄級別的容錯》
3)在infoQ和CSDN等技術論壇都有采訪和發表過文章
4)2015 China hadoop summit 的特約演講嘉賓
專業技能:
1)能熟練的運用Linux系統開發和shell編程,
2)精通java、熟悉python、R語言
3)熟悉struts、spring、hibernate開發
4)熟練運用mysql、oracle等關系型數據庫,Cassendra、mongoDB、Redis等NoSql數據庫
7)熟練運用flumeNG、scribe等日志收集工具
8)熟練運用ganglia和Nagios、openTSDB對hadoop集群進行監控
9)熟練運用storm、spark 分布式計算模型,spark Streaming、Mllib和graphx
10)精通MR的編程、Mahout、hbase、Oozie、Kafka、Impala、Tez、hive等應用
11)精通hadoop平臺的搭建、優化、監控和其生態系統組件的使用。
12)熟悉openstack和docker虛擬化技術
認證:
國考——軟件設計師(中級)—2009年
近期案例:
蘭州銀行,大數據平臺,架構師,2014年
內蒙移動,大數據平臺試點(Hadoop),架構師,2014年
遠傳電信(臺灣),Hadoop平臺優化解決方案和實施,架構師,2014年
招商銀行大數據咨詢項目規劃和設施,架構師 2015年
交通銀行大數據平臺規劃和設施,架構師 2015年
高德軟件,高德集團大數據中心的建設、從15個Hadoop節點經過5次的擴容到300+節點,機房換了兩個,負責Hadoop平臺的開發、優化、運維和給兄弟部門提供服務等,Hadoop部門經理,2011.03 -2013.01年
阿里巴巴大數據高級架構師,負責OPDS平臺架構、開發和運維 2013-2014.04年
課程費用
課程費用:5800元/人










